What is sound?
If we want to generate a tone, that, later, will be used in a musical context, we’ll need to generate a tone at a stable frequency. to do that we’ll need to understand how digital sound works. We’ll need to understand how sound works.
I’ll explain this in the reverse signal path, so let’s start with the question of what sound itself is.
Physics
Sound, fundamentally, is air particles being moved in a way that can be detected by your ear. Usually we talk about sound waves, which means that the particles are being moved back and forth in a wave function.
Here’s a very crude graphical representation of this I threw together in Processing real quick:
To generate sound, you’ll somehow need to get these air particles moving. You could do that by attenuating a string like on a guitar or in a piano, hitting a drum skin or a metal or wooden bar like in a marimba, but if we want to involve a computer here, it’s pretty obvious that we somehow need to convert electrical signals into these particle waves.
The device you’re looking for here is a loudspeaker. A loudspeaker has a magnetic coil which moves a large static magnet connect to a large membrane, also called the diaphragm, which then moves the air. The coil is driven by an analogue electric signal which is, essentially, an electric representation of the sound you’re hearing.

But how do we get from the digital domain to the analogue domain? We’ll need a DAC or Digital to Analog Converted which will turn a digital signal into an analogue signal. Nowadays, this is usually a small chip on your mainboard or on a soundcard. Here’s one specific chip:

But here you’re already seeing the main issue in this process - A digital signal is made off of discrete values at discrete moments in time - Analogue signals have nothing discrete about them, an analogue signal has an endless resolution in both the time and the amplitude domain * .
- This is not entirely true. Analogue signals do have some boundaries as well, for example, electronic components will have a certain bandwidth in which signals can get processed cleanly. Also, a loudspeaker has technical limitations - with limited power, you can move a heavy magnet only so fast, which is the main reason most advanced speaker systems use different speakers for different frequency ranges - a small speaker is only good at reproducing high pitches, a large speaker is only good at reproducing low pitches.
To make this not sound like shit, we’ll need to use a couple of tricks - First of all, not so tricky, both the time and the amplitude domain need to be high resolution enough so that the listener cannot hear the discreteness of the signals. To figure out how to do that, we first need to understand the boundaries of human hearing. Usually a good human ear can hear frequencies up to around 20 kHz. This gets worse the older you get as parts of your ear start to see some wear and tear and some people do hear higher frequencies, but this is a good baseline assumption. Ok, so large should our sample rate be? (meaning the number of different values per second) - Well, if the highest frequency we want to express is around 20 kHz, then it’s quite easy to assume that we probably need to double that. Let’s take a look at why that is. Imagine you want to express the highest frequency possible with a digital signal. You would want to essentially create a squarewave where each wave cycle is 2 “samples” long. Which gives you a tone at exactly half the sample rate.
But the digital signal of 20 kHz and the analogue signal look very different, right? Well, yes, they would, but if we know that the highest frequency we can express in a digital signal is half the sampling frequency, we can add analogue circuitry that will cut off frequencies past this point and end up with a signal that is much closer to the analogue representation.
This is the dumbed down version of what’s called the Nyquist-Shannon sampling theorem, which has a Wikipedia page with a lot of formulas, if you need to flex your maths muscle.
As you know, the CD, which was the first commercially successful digital audio format, settled at 44.1 kHz, which gives you a maximum frequency of 22.05 kHz, which is at least completely outside of my own hearing range.
For the amplitude, most people are unable to hear (given a flawless DA process) differences in resolutions beyond 16 bit for most music, but here the story is a bit more complicated, because the human ear has an incredible dynamic range, meaning how well the human ear can hear both very loud and very quiet. The more dynamic range music has (classical pieces often have an incredible dynamic range with very quiet and very loud passages), the more difficult it becomes to cram music into 16 bits.
Ok, so we’re now finally in the digital domain. So let’s generate our first tone.
Finally, let’s look at some code.
We’ll start with the simplest waveform we can generate in the digital domain. We’ve already seen it in the sampling frequency diagram, it’s of course a squarewave.
To generates something that can be heard by ordinary people, let’s cut the frequency down to a more manageable 440 Hz. Why that weird number? Well, 440 Hz is the so called Concert Pitch A, a more or less global standard for tuning instruments.
Okay, well, let’s talk about notes and pitches for a second, while we’re at it.
Most western music (important caveat!) is based on a scale of 12 so called half tones in an octave. The difference between an octave and the next is that the frequency doubles. So if the middle A is 440 Hz, the next A would be at 880 Hz, and the one below would be at 220 Hz.
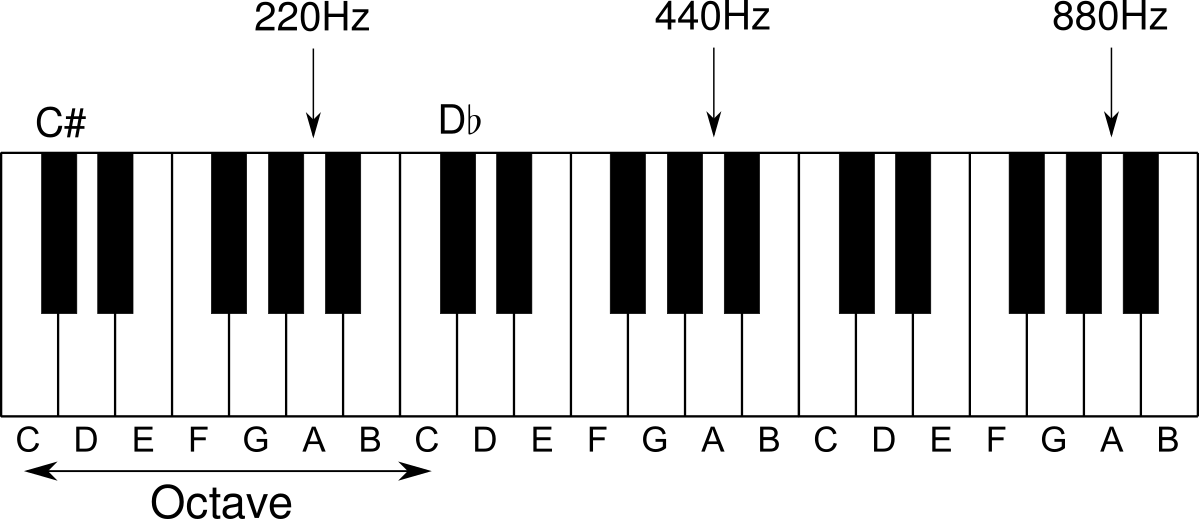
All the other half tones are derived by various ratios that unfortunately don’t add up perfectly. This leads to all kind of different compromises you can make to arrive at these 12 half tones and which scale or tuning you choose often also depends on your musical material. Most pop music uses the so called equal temperament which simply cuts the octave in twelve equal steps.
There’s a simple formula to convert notes into frequencies, but uh, it has a number as input - This is a so called MIDI note number and it makes working with notes really easy, it simply counts half tones from a very low C, so 12 would be the next C, then 24, 36 etc. The middle C is 60, so the concert pitch A is 96.
Okay, let’s finally go back to our tone. a note of 440 Hz has a period of 0.002272 seconds, which helps us because we can now determine that, given a sample rate of 44.1 kHz, each period of our wave is 100.227272727 samples long. Of course we could cheat and say that we would be ok with generating a tone with 441 Hz, because that would give us nice round numbers, but that would deny us an important lesson, namely the fact that it’s quite important to keep your precision. So here, again, is the ruby code for generating a 440 Hz rectangle tone for exactly one second:
SAMPLING_FREQUENCY=44100
FREQUENCY=440
in_cycle = 0
samples = SAMPLING_FREQUENCY.times.map do
period = SAMPLING_FREQUENCY / FREQUENCY.to_f
output = in_cycle > 0.5 ? -1.0 : 1.0
in_cycle = (in_cycle + (1.0 / period)) % 1.0
output * 0.5
end
print samples.pack('e*')
We’ve essentially built what in Synth terms is called an “Oscillator”. we’re using the in_cycle variable as a counter that counts from 0 to 1 for each period, and then, at exactly 0.5, we’re switching the polarity of our output.
There’s one important caveat here that I’ll ignore for the rest of this text, but is important to know: A pure square wave, as we’re generating one here, has, by definition, an endless amount of so called overtones, expanding in the frequency spectrum way beyond our Nyquist-Shannon limits. This can lead to all kinds of weird artefacts (TODO: Find good explanation) which can be avoided by properly bandwidth limiting (essentially meaning filtering out all frequencies above the Nyquist-Shannon limit.) the waveform.